《社區級數據科學及其影響範圍:超越新奇平方》(Community-level data science and its spheres of influence: beyond novelty squared)
By Brittany Fiore-Gartland and Anissa Tanweer
Source: https://escience.washington.edu/community-level-data-science-and-its-spheres-of-influence-beyond-novelty-squared/
筆者前言: 因為社區時間銀行系統與單位網絡在群聚社會資本的重要關聯應用,與早先在「社群資源規劃」 (C: CRP, Community Resource Plan)理論,建模,系統開發及計劃項導入等創新應用項目,尤其在《數位學習歷程》相關創新應用上,找到了進入社區/社群以時間為計值單位的交換與交易模式 (或是 CES 6種交易/交換模式),而非是傳統法幣/貨幣計值單位。即以,社區《數位學習歷程》系統與單位網絡在群聚人力資本與文化資本,期轉化社會資本,進而經濟資本與環境資本等不同資本型態的轉化果效控管。
其中,如何將《按需學習: T型技能履歷與技能方塊簡介》相關創新應用,導入在社區/社群層級 (Community-level) 在建立與強化人力資本與文化資本是至為重要的。尤其,若是創新管理全生命週期6+1個階段,進入社區/社群單位,是最後一哩路。那麼期這篇由美國華盛頓大學(University of Washington, Seattle, Washington, USA) 所出版的《社區級數據科學及其影響範圍:超越新奇平方》(Community-level data science and its spheres of influence: beyond novelty squared),關於在數據科學學科上的論述,能夠進一步充實在社區級資源規劃的關聯論述與實際應用: 即如何《建造 T, Π, Γ, Μ 型技能人才網絡,邁向社區級數據科學的創新應用!》 (Building up T, Π, Γ, and Μ-typed Skills Network toward Community-level Data Science Innovation!)
另請參閱: 相關 《數位學習歷程》>>《T型技能》(T-shaped Skills) 關鍵字文章
最後,《白石CES時間銀行社群雲》(KCE2CES Community Cloud) 致力於全年無休《誠如台灣總統盃黑客松》社區/社群創新實踐模式! 歡迎來自台灣與台灣以外的法人/自然人單位,一起來參予實踐「e 起共善經濟」! 因為,在這裏,我們沒有提案截止日,只有致力社區/社群SDGs永續創新! 歡迎您的法人或是自然人單位,同樣在致力邁進聯合國永續發展目標 (UN Sustainable Development Goals, SDGs 17) 創新管理最後一哩路: 社區/社群單位者,與我們聯絡。
本文開始:

數據科學有很多特徵,但在學術界,它經常被談論為推動方法論和領域科學的極限,加州大學天文學教授喬什·布魯姆 (Josh Bloom) 說。伯克利,被稱為“新奇平方”(Novelty Squared)。布魯姆認為這是“現代跨學科科學合作的巨大挑戰”。學術界對數據科學的理想化表徵還體現在從在單一領域擁有深厚專業知識的傳統 T 型科學家轉變為在某一領域和方法論方面擁有深厚專業知識的 Π (Pi) 型科學家的想法。科學(由 Alex Szalay 創造並在此處和此處討論)。作為 Π 型數據科學家,他們準備在多個學科軌跡中進行創新。 Bloom 和其他人認為,這些新奇平方和 Π 形科學家的特征代表了數據科學的“獨角獸”。
理想數據科學家的神話般的、難以捉摸的本質得到了我們的民族志實地考察的支持。在整個數據科學環境中尋找這些所謂的“數據科學家”時,我們幾乎找不到任何一致認定為“數據科學家”的人。我們更經常地發現,“數據科學家”是一個部分的、關係性的身份,是眾多身份中的一層。我們遇到了大量的數據科學,它們出現在眾多不同形狀的科學家之間的相互作用網絡中,從 T 到 Γ (Gamma) 到 Π 甚至 Μ (Mu) 形!個人大多不認為自己是特別 Π 型的,這一類別很多只屬於極少數在多個領域取得了非凡專業知識和貢獻的人。正如我們中的一個人在別處討論過的那樣,也許數據科學的一個更現實的特徵包括一個不同形狀的科學家在社區層面實踐數據科學的網絡。
網絡(Network)
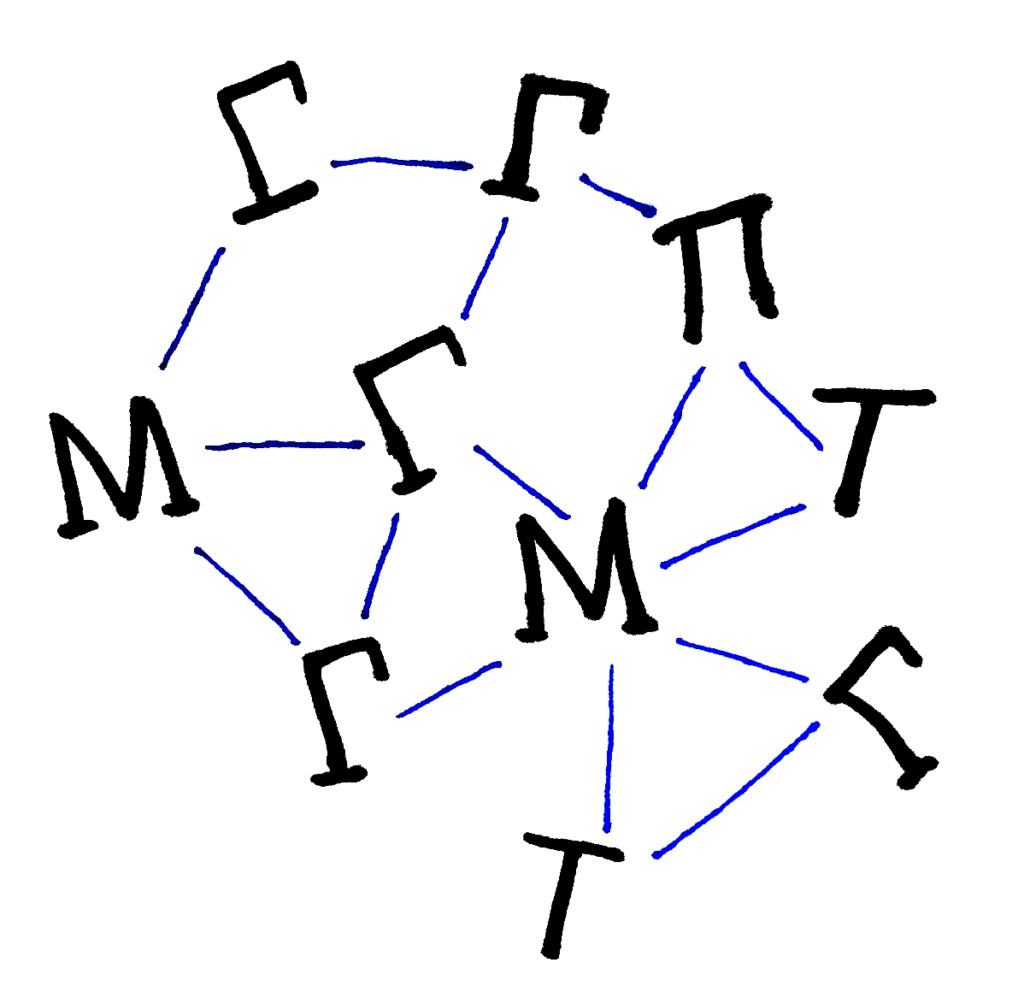
T, Π, Γ, Μ 網絡。社區級數據科學的網絡視圖揭示了實踐數據科學的 T 形、Γ 形、M 形和 Π 形科學家的混合體。
知識共享許可本圖片由 Brittany Fiore-Gartland 提供,已根據知識共享署名-非商業性使用 4.0 國際許可協議獲得許可
為了更準確地了解實踐數據科學是什麼樣子,我們將自己嵌入到華盛頓大學電子科學學院的數據科學孵化器 (DSI) 計劃中,以便我們可以觀察整個校園的數據科學合作的橫截面。 DSI 是一個計劃,旨在將數據科學家和領域科學家聚集在一起,在一個學術季度的過程中開展集中、密集、協作的項目。該計劃向整個校園的科學家徵求對需要數據科學專業知識的項目的建議。然後,被接受的申請人將與 eScience Institute 的一兩個數據科學聯絡員配對。
作為人種學家,我們是 DSI 的參與者觀察員,並發現它代表了一種很有前途的模式,可以培養我們所說的社區級數據科學。我們發現 DSI 沒有培育體現單一、理想的“數據科學家”的獨角獸,而是在社區層面促進數據科學實踐,這樣工作就分佈在基於領域和方法的方法中,並發生在這些不同形式的交叉點上。專業知識。除了承認 DSI 在推進其特定研究項目中的作用外,參與者還明確意識到他們參與了學習成為數據科學社區一員意味著什麼的過程。換句話說,參與者將數據科學視為一種文化實踐。
因此,新穎性平方模型不足以充分錶徵 DSI 相互作用。我們的受訪者並沒有單獨談論數據科學的價值,甚至沒有首先談論同時推動領域知識和計算方法的已知極限的價值。相反,他們將數據科學中的“小說”想像成能夠影響一系列日常工作實踐並擴展一系列科學和專業可能性的能力。
該計劃提供了一個窗口,可以了解一系列具有重要價值的數據科學合作,而所有這些合作都沒有以新穎的平方方法為特徵。我們如何理解這一系列互動並理解參與者想像的不同動機和價值觀?根據我們對該計劃的人種學觀察和對所有參與者的採訪,我們將我們聽到的參與者想像並歸因於數據科學的不同類型的價值分為六個影響範圍。
球體影響範圍 (Spheres of Influence)
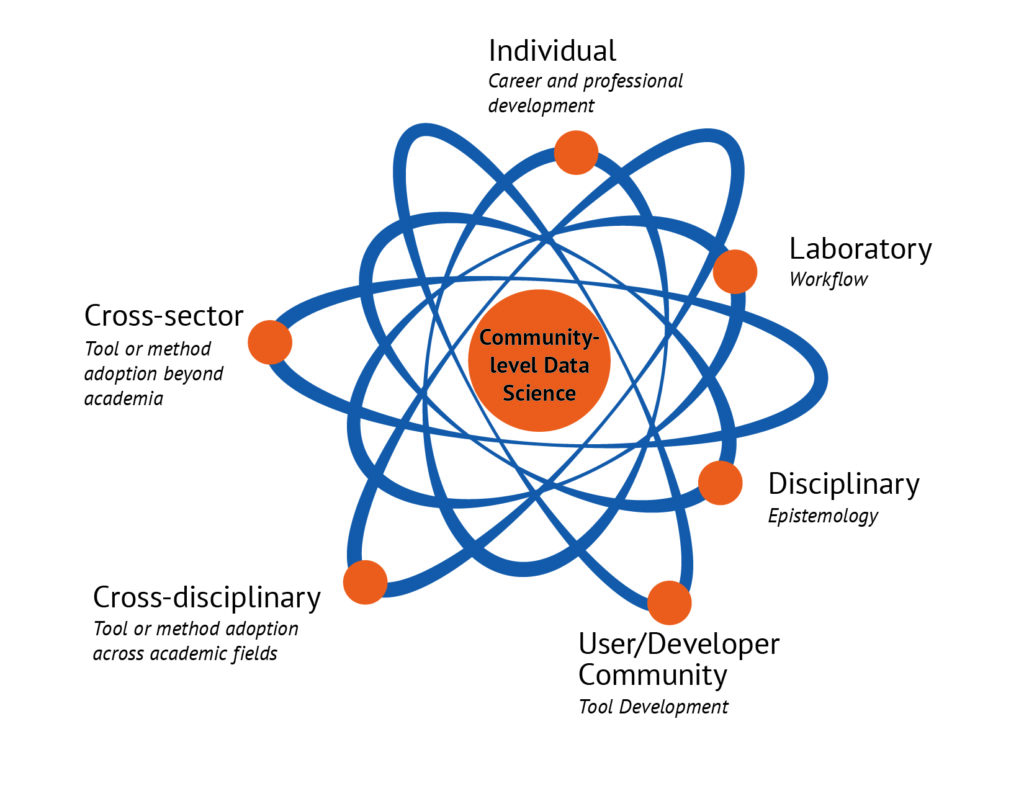
知識共享許可 此圖像由 Paul Roberts 提供,已根據知識共享署名-非商業性使用 4.0 國際許可協議獲得許可
個人 (Individual)
一些參與者告訴我們,數據科學通過為他們提供不尋常的技能或使他們能夠生成新的數據集,幫助他們與各自領域的其他學者區分開來。例如,一位參與者告訴我們:
“[當]你在就業市場上發表了一篇你將成為獨立作者的論文,並且使用這些預先打包的數據集變得越來越少。您開始需要提供新數據,回答任何問題,找到一份好工作。”
在這種情況下,數據科學被想像為通過為研究人員提供技能、工具和數據來影響個人領域,這些技能、工具和數據可以幫助他們推進職業和職業目標。
實驗室(Laboratory)
其他參與者來到數據科學孵化器,希望獲得新技能並學習新工具或系統,他們可以帶回實驗室或合作研究小組,以優化他們的工作流程。對於一位參與者來說,這是關於使用在孵化器中學到的工具和技術來自動化涉及手動處理文件的現有工作流程。對於另一位參與者來說,這是關於使用 Git 為他們的實驗室帶來更加無縫和透明的工作流程。用這位參與者的話來說:
我想做的是建立一個更好的基礎設施。編程是在 Git 上進行的,所以我可以查看 [實驗室成員] 的程序。我可以下載它們。我可以檢查它們。 [….] “我相信這個代碼嗎?我不相信這個代碼嗎?這一堆黑客多少錢?這個整潔的代碼多少錢?” [….] 我知道我想開始使用 Git。我沒有使用 Git,所以然後將 [the] 實驗室轉移過來做它,[當你] 甚至不知道如何自己使用它時,它永遠不會工作。”
這個人在數據科學孵化器的經歷中最重要的是獲得了新的技能和工具,這將使她能夠簡化和優化整個教師和學生研究團隊的工作程序。對於一些參與者來說,這不一定是短期內的科學進步;相反,它是關於長期投資於科學進步和生產力。這種觀點突出了社區級數據科學影響實驗室領域的潛力。
學科範疇(Disciplinary)
有時,參與者將數據科學視為在其學科內發展理論的新方法。一位參與者告訴我們:
“[我所在領域的傳統理論家] 說‘這是我的回歸模型。我猜測的這些 x 基本上很重要……然後我將使用該模型來預測 y。 從來沒有一個過程可以剔除任何可能不重要的回歸量。我們認為這是一種非常古老的做法。在我們擁有可以告訴我們這些信息的機器學習技術之前,我們就是這樣做的。”
這個人認為數據科學提供了一種新的認識方式,或者將認識論上的新穎性引入他的特定領域。所以在這種情況下,我們可以認為數據科學正在影響學科領域。
用戶/開發者社區(User/Developer Community)
人們有時發現的另一個新奇領域是他們對數據科學工具開發的貢獻。一位參與者這樣描述她的經歷:
“……我是唯一進行這些計算並通過 [新開發的基於雲的數據管理系統] 進行大量數值計算的人之一。我認為很多其他查詢都在查看文本。這是一個不同的焦點。我正在為他們找到一些非常好的錯誤。“
因為她所做的貢獻可能會影響任何使用或開發新工具的人,在這種情況下,我們將社區級數據科學描述為影響用戶/開發人員社區的領域。
跨學科(Cross-disciplinary)
有時,研究人員正在開發新的方法來檢查多個領域中常見的研究對象。一位正在開發工具和方法來分析 Internet Archive 上整個文本語料庫的參與者就是這種情況:
“在我們參加的這次會議上,有一群人試圖[在互聯網檔案館]進行鏈接分析……。我一直在看文字。我告訴他們……我會把我做的所有東西都發給他們,他們對此非常興奮,因為他們想開始查看文本,但他們還沒有考慮這樣做,因為它有 90 TB文本。你怎麼看?!”
在這種情況下,正在開發的方法和工具可以應用於跨不同學術領域生成和分析的類似數據。因此,我們可以將社區級數據科學視為潛在影響跨學科領域。
跨部門(Cross-sector)
有時,我們研究的參與者會談論他們正在開發的新型數據科學工具和方法如何應用於學術界以外的問題。這個想法是由一位參與者表達的,他認為他的分析時間序列的算法可能對其他類型的數據有商業應用:
“例如,我很想創辦一家公司,試圖對來自可穿戴設備或物聯網的所有這些時域流進行建模。這些東西在哪裡產生這些數據流,人們不一定在聽。但如果他們是——如果你有合適的軟件來監聽這些流——你實際上可以理解發生了什麼。”
因為此人設想採用為學術研究而開發的軟件並將其調整用於商業環境,所以我們可以說數據科學的想像影響正在跨學術和商業部門的跨部門領域發生,以及作為公共和私營部門。
邁向社區級數據科學(Toward a community-level data science)
正如這些例子所示,我們發現對數據科學價值的廣泛想像往往不是“新奇平方”的水平。可以肯定的是,如果沒有孵化器,許多 DSI 項目將變得難以處理。提出參與者不能或不會提出的研究問題。在某些情況下,這種新穎的科學需要數據科學聯絡人的特定投入和貢獻,而在其他情況下,這種新穎的科學是通過專門的時間從數據科學經典中全面學習工具和技術來支持的。但孵化器參與者通常將他們的重大突破描述為數據科學聯絡人的微不足道的任務。換句話說,我們沒有看到同時推動領域知識和計算方法前沿的數據科學的理想化想像。
當這些項目似乎確實在追求新穎性時,一些參與者對這種雙重軌跡感到矛盾,並確定了一方面開發新的計算工具和技術的任務與做最有利於他們的科學的任務的任務之間的緊張關係。另一方面。但這是另一部分的主題。
儘管如此,正如我們所展示的,對於這些參與者來說,在 DSI 中完成的數據科學工作被認為是在一系列領域內具有新穎性和變革性的。我們觀察到的許多研究人員都看到了適應數據科學社區的價值。他們談到學習數據科學的語言、工具、流程和規範將如何促進他們的職業發展,讓他們跟上各自領域的趨勢,優化他們的工作程序,改變他們的學科和分支學科的曲目,並建立聯繫他們的研究所需的一系列專業知識和資源。除了孵化科學項目外,DSI 還在數據科學社區內培養研究人員,讓他們沉浸在數據科學的文化語言中,學習如何像數據科學家一樣思考以及如何成為數據科學社區的一部分。因此,如果我們想了解數據科學在學術界的演變,我們需要認識到,這不僅僅是發展個別研究人員採用新方法的能力,還在於打造可以重塑的社區級數據科學。學院的文化輪廓。